

 如果结果不匹配,请
如果结果不匹配,请 
 更多“什么是财务预警的多变量模型?简要说明奥尔曼(Altman)模…”相关的问题
更多“什么是财务预警的多变量模型?简要说明奥尔曼(Altman)模…”相关的问题
A.企业的自身经营发展情况不同,其财务危机发生的表现往往也有区别,而财务预警模型不能因企业而异
B.财务危机预警模型往往需要涉及多个财务变量,而数据的收集难度随着变量数增多而增大
C.企业的财务危机问题十分复杂,对指标的简单数量分析会因出发点不同或相关参照因素的不同而得出大不相同的结论
D.不同计算口径,也限制了直接应用财务危机预警模型的企业范围
E.财务预警模型只能提供关于财务危机发生可能性的线索,而不能确切告知是否会发生
估计p:科克伦-奥克特迭代程序。作为对此程序的一个说明,考虑双变量模型:

及AR(1)模式

于是科克伦和奥克特推荐如下步腺来估计ρ。
(1)用通常的OLS方法估计方程①并得到残差ut。顺便指出,你可以在模型中包含不止一个X变量。
(2)利用第1步得到的残差做如下回归:

这是方程②在实证中的对应表达式。
(3)利用方程③中得到的 ,估计广义差分方程(129.6)。
,估计广义差分方程(129.6)。
(4)由于事先不知道方程③中得到的 是不是ρ的最佳估计值,所以把第3步中得到的
是不是ρ的最佳估计值,所以把第3步中得到的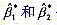 值代入原回归①,并得到新的残差解
值代入原回归①,并得到新的残差解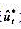 为
为


(5)现在估计如下回归

它类似于方程③,并给出p的第二轮估计值。由于我们不知道p的第二轮估计值是不是真实p的最佳估计值,所以我们进入第三轮估计,如此等等。这正是科克伦-奧克特程序被称为迭代程序的原因。我们该把这种(愉快的)轮回操作进行到什么程度呢?一般的建议是,当p的两个相邻估计值相差很小(比如不是0.01或0.005)时,便可停止迭代。在工资-生产率一例中,在停止之前约需要3次迭代。
a.利用科克伦-奥克特迭代程序,估计工资生产率回归(12.5.2)的p.在得到ρ的“最终”估计值之前需要多少次迭代?
b.利用a中得到的p的最终估计值,在去掉第一次观测和保留第一次观测的情况下,估计工资生产率回归。结果有何差异?
c.你认为在变换数据以解决自相关问题时保留第一次观测重要吗?
根据1899~1922年美国制造业部门的年度数据,多尔蒂(Dougherty)获得如下回归结果:

a.回归(1)中有没有多重共线性?你怎样知道?
b.在回归(1)中,1ogK的先验符号是什么?结果是否与预期相一致?为什么?
c.你怎样替回归的函数形式(1)做辩护?(提示:柯布-道格拉斯生产函数。)
d.解释回归(1)在此回归中趋势变量有什么作用?
e.回归(2)的道理何在?
f.如果原先的回归(1)有多重共线性,是否已被回归(2)减弱?你怎样知道?
g.如果回归(2)被看作回归(1)的一个受约束形式,作者施加的约束是什么呢?(提示:规模报酬)你怎样知道这个约束是否正确?你用哪-种检验?说明你的计算。
h.两个回归的R2值是可比的吗?为什么?如果它们现在的形式不可比,你会怎样使得它们可比?
在发现肺癌与吸烟有关的首批论文中,有一篇是由多尔(1955)发表的。他调查了1930年及20年后11个国家中人均香烟消费量。这是很自然的事。因为要想看到其间的因果关系,就必须经过数年的时间。由于1930年吸烟的妇女人数很少,所以把吸烟人数与男性死亡率相联系似乎是很合适的。表2一l就是根据多尔的一些重要调查结果改编而成的。
表2-1不同国家香烟消费量与死亡人数
| 国 家 | 1930香烟消费量 | 1950肺癌死亡人数/百万 |
| 澳大利亚 | 480 | 180 |
| 加拿大 | 500 | 150 |
| 丹麦 | 380 | 170 |
| 芬兰 | 1100 | 350 |
| 英国 | 1100 | 460 |
| 荷兰 | 490 | 240 |
| 冰岛 | 230 | 60 |
| 挪威 | 250 | 90 |
| 瑞典 | 300 | 110 |
| 瑞士 | 510 | 250 |
| 美国 | 1300 | 200 |
(1)这两组数据将会说明什么问题?
(2)把这两组调查结果绘成曲线,从曲线上可以看出什么?
(3)用附录B给出的皮尔逊r公式,计算出这两个变量之间准确的相关系数。你得到的相关系数是怎样的,其大小与符号各是什么?















